




Ⅰ. 서론
추천 시스템(recommendation system)은 다양한 정보를 활용하여 사용자에게 개인화된 콘텐츠를 추천하는 정보 필터링 도구를 의미한다(Roy & Dutta, 2022). 추천 시스템은 1990년대 타인의 의견 및 행동을 반영한 메일 필터링이나 사용자의 평점에 기반한 뉴스 필터링 등의 기술로 등장하였다. 이후 기술의 발전과 함께 추천 시스템은 다양한 분야로 확장되기 시작하였다. 1999년 아마존이 전자상거래 기업 중 최초로 대규모 추천 기술을 도입하였고, 2006년부터 2009년까지 진행된 Netflix Prize는 영화의 평점을 예측하는 연구를 촉진시키며 다양한 머신 러닝 기술이 적용된 추천 시스템의 연구가 지속적으로 발전하고 있다.
특히 추천 시스템은 B2C(business-to-consumer) 분야에서 활발하게 연구되고 있다. 소비자들이 방대한 정보로 인해 제품과 서비스의 선택에 어려움을 겪는 상황 속에서 추천 시스템은 소비자들에게 개인화된 정보를 선별하여 제공함으로써 이러한 문제 해결에 핵심적인 역할을 담당하기 때문이다(Fayyaz et al., 2020). 이에 따라 다양한 추천 모델에 대한 연구(Alamdari et al., 2020)와 더불어 고객 경험의 개선 및 만족도 향상(Roy & Dutta, 2022), 판매 다양성 증가(Fleder & Hosanagar, 2007), 마케팅 전략의 최적화 및 비용 효율성 증가(Ko et al., 2022) 등 추천 시스템 도입에 따른 효과도 활발하게 연구되고 있다.
반면, B2B(business-to-business) 분야에서의 추천 시스템 연구는 상대적으로 부족하다. 일반적으로 B2B에서 발생하는 거래 빈도는 B2C보다 빈도가 낮아 데이터의 수집 및 분석이 어려우며(Meng et al., 2024), 기업 간 거래 정보는 기업의 전략이나 조건 등 민감한 정보를 포함하고 있어 확보가 어려워 B2B 분야의 추천 시스템 연구는 매우 어려운 상황이다(Cho et al., 2023). 또한 B2B 유통 분야는 같은 판매자가 판매하는 상품일지라도 구매자별 거래 조건에 따라 구매 가격이 다르며, 구매자의 특성에 따라 구매하는 상품의 종류와 수량이 큰 차이를 보이는 등 B2C 분야에 비해 거래 환경이 복잡한 모습을 보인다(Saha et al., 2014). 그러나 대규모 상품 정보로 인해 발생하는 정보 과부화 문제를 해결할 수 있으며, 거래 이력이나 검색 기록 등의 정보 기반 맞춤형 추천을 통해 고객의 의사결정을 지원하는 등 B2B 유통 분야 추천 시스템은 다양한 활용성을 가지고 있어 연구의 필요성이 높다(Nia et al., 2019).
특히, 중소 유통 소매점은 일반적으로 과거 판매실적과 상권 특성을 기반으로 발주를 진행하지만, 이러한 내부 정보만으로는 빠르게 변화하는 소비 트렌드나 신규 상품, 비정형적 수요에 효과적으로 대응하기 어렵다는 한계가 존재한다. 이에 추천 시스템을 활용할 경우, 유사 소매점의 구매 데이터를 기반으로 기존 방식으로는 포착하기 어려운 수요를 예측하고, 구매 결정을 지원함으로써 정보 부족에 따른 제약을 보완할 수 있다. 또한 유사 소매점과 비교해서 예측한 주문 상품과 수량과 실제 주문 상품과 수량이 차이가 난다면 원인과 대책을 수립하는 데 도움이 될 수 있다.
이에 본 연구에서는 중소유통공동도매물류센터를 이용하는 소매점의 거래 정보를 기반으로, B2B 유통 분야에서 추천 시스템의 적용 가능성을 실증적으로 검토하고자 한다. 이를 위해 특이값 분해(singular value decomposition)를 활용한 협업 필터링 기반 추천 시스템을 구축하였으며, 성능 비교를 위해 유사도 기반 모델, 완전 특이값 분해(full SVD), 절단된 특이값 분해(truncated SVD) 알고리즘을 함께 적용하였다. 나아가 콘텐츠 기반 필터링을 결합한 하이브리드 추천 시스템을 통해 추천 정확도의 개선 여부를 확인하고, 이를 바탕으로 B2B 유통 분야에서의 추천 시스템 활용 방안을 제시하고자 한다.
Ⅱ. 이론적 고찰
초기 추천 시스템은 추천의 생성 방법에 중점을 두어 다양한 사용자들이 제공한 정보를 수집하고 분석하여 추천이 필요한 수신자에게 추천 정보를 전달하는 시스템으로 정의되고 있다(Resnick & Varian, 1997). 이후 연구자들은 점차 발전되는 추천 시스템의 개념을 확장하여 추천이 생성되는 방식과 관계없이 개인화된 방식으로 사용자에게 흥미롭거나 유용한 정보를 안내하는 시스템(Burke, 2002)으로 정의하였다. 나아가 Adomavicius and Tuzhilin(2001)은 추천 시스템을 추천의 대상이 되는 항목(item)과 사용자의 유용성 함수로 공식화하여 각 사용자에게 가장 유용한 항목을 추천하는 시스템으로 정의하였다. 추천 시스템에 대한 연구가 지속되면서 범위가 확대되고 있으나 변하지 않는 핵심 개념은 사용자가 선호하는 특정 항목을 선택할 수 있도록 개인화된 선택지를 제시한다는 것이다.
주요 추천 시스템 유형으로 콘텐츠 기반 필터링(content-based filtering), 협업 필터링(collaborative filtering), 하이브리드 접근법(hybrid approaches) 등이 연구되고 있다. 먼저 콘텐츠 기반 필터링은 사용자가 선호했던 항목의 특성을 활용하여 유사한 항목을 찾아 추천하는 방식이다(Thorat et al., 2015). 예를 들어 영화의 특성을 감독, 배우, 장르 등으로 구분할 때, 사용자가 특정 영화를 긍정적으로 평가하면 해당 영화와 유사한 특성을 지닌 다른 영화가 추천되는 형태이다. 콘텐츠 기반 필터링은 추천 과정이 간단하고 명확하며 사용자의 변화하는 선호도를 빠르게 반영할 수 있다는 장점을 지닌다. 그러나 정확한 추천을 위해서는 항목과 관련된 다양한 지식이 필요하고, 사용자의 기존 선택이나 관심사의 확장에 한계가 존재하며, 새로운 사용자가 추가되면 과거의 선호도가 존재하지 않아 추천이 제대로 이루어지지 않는 콜드 스타트(cold start) 문제가 발생할 수 있다는 단점이 존재한다.
협업 필터링은 다수의 사람이 같은 항목을 선택한다면 다음 선택도 같을 가능성이 크다는 가정에 기반하여 추천 대상과 유사성이 높은 사용자 집단의 선호도를 기반으로 추천 항목을 예측하는 방식이다(Singh et al., 2020). 협업 필터링의 일반적인 방법은 추천을 위해 먼저 사용자와 항목 간의 상호작용(평점, 클릭 여부, 구매 여부 등)을 행렬의 요소로 가지는 사용자-항목 상호작용 행렬이 구성된다. 구성된 행렬을 바탕으로 비슷한 사용자 또는 항목을 찾고 해당 집단의 선호도를 활용하여 추천하거나, 상호작용 행렬을 사용자와 항목 간 잠재 요인(latent factors)으로 분해 및 학습하여 추천 항목을 도출하는 방식 등이 존재한다. 협업 필터링의 장점은 추천을 생성하기 위해 항목에 대한 지식이 필요하지 않으며 기존 선호도를 확장하여 다양한 항목의 추천이 가능하다. 그러나 새로운 사용자나 항목이 추가되면 이에 대한 정보가 전혀 없어 추천을 진행하기 어려운 콜드 스타트 문제가 발생한다. 이러한 경우 추천 과정이 처음부터 진행되거나, 새로운 사용자와 항목의 잠재요인을 다시 설정해야 하거나 혹은 새로운 사용자와 항목에 대한 새로운 자료가 들어올 때까지 기다리거나 다른 추천 시스템 유형 활용해서 일단 새로운 사용자와 항목에 대한 추천을 진행해야 한다.
하이브리드 접근법은 개별적인 추천 방법의 한계를 보완하기 위해 두 개 이상의 추천 시스템을 결합한 방식이다(Thorat et al., 2015). 결합 방식은 서로 다른 추천 시스템을 통해 추천된 항목을 결합하여 최종 추천 항목을 도출하는 가중치 접근법(weighted approach), 특정 조건에 가장 적합한 추천 시스템을 선택하여 최종 추천 항목을 제공하는 전환 접근법(switching approach), 여러 추천 시스템의 추천 결과를 혼합하여 제시하는 혼합 접근법(mixed approach) 등이 존재한다. 결합되는 추천 시스템은 고정되지 않고 서로 다른 추천 시스템의 강점을 최대화하기 위하여 다양하게 결합될 수 있다. 이를 통해 추천 시스템의 정확성을 높일 수 있으며, 콜드 스타트나 희소성으로 인해 발생하는 문제를 완화시킬 수 있다(Parthasarathy & Sathiya, 2023).
최근에는 딥러닝을 적용한 추천 시스템 연구도 활발하게 진행되고 있다(Zhang et al., 2019). 딥러닝은 추천 시스템의 한계를 극복하고 사용자와 항목 간의 복잡한 상호작용을 효과적으로 모델링할 수 있기 때문이다. 특히 딥러닝 기반 추천 시스템은 비선형적인 데이터 관계 학습에 유리하고, 고차원 데이터에서 잠재 요인을 추출할 수 있으며, 텍스트뿐만 아니라 이미지, 시계열 등 다양한 형태의 데이터를 처리할 수 있다는 강점을 보인다. 그러나 이러한 강점에도 불구하고 대규모 데이터 처리 시 높은 계산 비용이 필요하고, 학습 데이터에 지나치게 적합하여 일반화 가능성이 저하될 수 있으며, 전통적인 모수 구조형태의 모델에 비하여 결과 해석이 어려울 수 있다는 단점이 존재한다.
앞서 언급한 것과 같이 콘텐츠 기반 필터링의 장점은 간단 명확하며 사용자 선호도를 빠르게 반영할 수 있다는 장점을 가지고 있으나, 새로운 추천 항목으로 확장의 한계 및 콜드 시스템 문제가 발생할 수 있다. 반면 협업 필터링 추천 시스템은 과거 거래 내역을 바탕으로 소매점의 구매 행동 및 상품과의 상호작용 분석을 통해 추천 정확도 향상에 유리하며, B2B 거래 정보에서 자주 발생하는 희소성 문제를 해결할 수 있기 때문이다(Adomavicius & Tuzhilin, 2001; Shetty et al., 2024). 특히, 소매점의 기존 선택 이외의 새로운 상품에 대한 추천이 가능하며, 상품에 대한 명확한 정보가 없어도 추천이 가능하다는 실무적인 이점을 지닌다. 이에 본 연구에서는 협업 필터링을 중심으로 추천 시스템을 구축하였다. 그러나 여러 이점에도 불구하고 협업 필터링 추천 시스템은 새로운 사용자나 항목이 추가될 경우 이에 대한 정보가 불충분하여 사용자의 선호를 제대로 파악하기 어려워 추천의 정확도가 떨어지는 콜드 스타트 문제가 발생할 수 있다. 따라서 협업 필터링과 콘텐츠 기반 필터링을 결합한 하이브리드 추천 시스템을 구축하여 콜드 스타트 문제가 개선된 추천 시스템까지 제안하고자 한다.
협업 필터링 추천 시스템이 비슷한 사용자들을 찾고 이를 바탕으로 추천을 생성하는 방법은 크게 메모리 기반(memory-based)과 모델 기반(model-based)으로 구분된다. 먼저 메모리 기반 방법은 사용자나 항목 간의 유사도를 기반으로 추천이 생성된다. 사용자 유사도는 특정 사용자와 유사한 선호도(상호작용 즉 평점, 클릭 여부, 구매 여부 등)를 가진 사용자가 선호했던 항목을 바탕으로 계산되며, 항목 유사도는 특정 사용자가 선호했던 다른 항목과 유사한 항목을 기준으로 계산된다. 이때 유사도를 계산하는 방법으로는 코사인 유사도(cosine similarity) 또는 피어슨 상관계수(pearson correlation) 등이 존재한다(Desrosiers & Karypis, 2010; Jain et al., 2020). 유사도를 계산하는 대상과 방법에 따라 일부 차이가 존재하지만 기본적으로 두 사용자 또는 두 항목 간의 유사도를 계산한다. 본 연구에서는 사용자 유사도 기반 모델을 비교모델로 사용하였다. 사용자 유사도 기반 모델에서는 추천의 대상이 되는 사용자와 가장 유사한 명의 사용자의 선택을 기반으로 추천 항목이 생성되며 수식은 (1)과 같다.
는 추천의 대상이 되는 사용자 u의 항목 i에 대한 예상 선호도이며, 는 사용자 u의 평균 선호도, Rv,i는 유사한 사용자 v의 항목 i에 대한 선호도, 는 사용자 v의 평균 선호도, sim(u, v)는 사용자 u와 사용자 v간의 유사도, N(u)는 사용자 u와 유사도가 가장 높은 N명의 사용자 집합을 의미한다. 이때, 5점 만점을 기준으로 어떤 사용자는 대부분 5점을 부여하는 반면, 어떤 사용자는 대부분 3점을 부여하는 등 선호도를 평가하는 기준이 상이할 수 있다. 이를 보정하기 위해서 평균 선호도를 기준으로 유사 사용자의 선호도 편차를 반영하여 예상 선호도를 계산한다.
이렇게 계산된 선호도를 바탕으로 k개의 추천 항목이 생성된다. 이때 사용자별로 추천 항목의 개수 k를 결정하는 방법은 일반적으로 유사도가 가장 높은 k개를 선택하는 K-최근접 이웃(K-nearest) 방식이나 특정 유사도 이상의 모든 사용자 또는 항목을 선택하는 임계값 방식 등이 존재한다(Nguyen et al., 2023; Shardanand & Maes, 1995). 추천 항목 개수를 결정하는 방법은 모델 기반 방식에도 동일하게 적용할 수 있다.
모델 기반 방식은 사용자-항목 행렬을 분석하여 추천을 제공한다(Casillo et al., 2023). 사용자-항목 행렬을 분석하기 위해 주로 행렬 분해가 주로 활용된다. 이는 차원 축소(dimensionality reduction)라고도 하며 주요 정보를 유지함과 동시에 분석에 활용되는 데이터의 양을 축소하기 위해 활용된다. 차원 축소를 바탕으로 추천 항목을 생성하는 과정은 먼저 앞서 언급했던 것처럼 사용자-항목으로 구성된 N×M 행렬 R을 구성하게 된다. 이때 사용자와 항목 간의 상호작용(평점, 클릭 여부, 구매 여부 등)이 이루어지지 않는 경우 Rui는 0으로 저장되기 때문에 실제 상황에서 R은 대부분이 0의 값을 가지는 희소 행렬로 나타난다. 구성된 행렬 R에 사용자의 취향과 항목의 특성을 분류하는 K개의 잠재 요인을 투입하여 차원을 축소시킨다. 기존 행렬 R은 다음 수식(2)와 같이 두 개의 행렬 곱으로 근사값으로 변화시킬 수 있는데, 이때 W는 N×K 행렬, V는 K×M 행렬로 각각 사용자의 취향과 항목의 특성에 대한 정보를 K의 숨겨진 잠재 요인으로 표현한다.
WV는 사용자의 취향과 항목의 특성 간의 적합성으로 사용자 u가 항목 i를 선호할 가능성을 나타낸다. 잠재 요인의 수 K가 N 및 M보다 작을 경우 행렬 R에서의 NM은 NK+KM으로 줄어들어 행렬 R을 두 행렬의 곱으로 행렬 분해할 수 있다. 이에 주로 활용되는 방법은 주성분 분석(principal component analysis), 비음수 행렬 분해(non-negative matrix factorization), 확률적 행렬 분해(probabilistic matrix factorization), 특이값 분해 (singular value decomposition) 등이 있으며, 이중 특이값 분해는 평가 행렬을 특이값으로 분해하는 방법으로, 추천 시스템에서 널리 활용되는 방법이다(Gu et al., 2020). 특이값 분해를 활용하여 행렬 분해를 하면 수식(3)과 같이 R이 분해되며, 여기서 ∑는 K×K의 대각행렬로 R 행렬의 특이값이 포함된다.
이때 K값에 따라서 차원의 축소 정도가 결정된다. K값이 N 또는 M 중 작은 값과 동일할 경우 차원이 축소되지 않는 완전 특이값 분해라고 한다. 이를 활용할 경우 행렬 R의 모든 정보가 보존되기 때문에 데이터의 손실 없이 계산이 가능해진다. K값을 N 또는 M 중 작은 값보다 더 작은 값으로 설정하면 ∑는 특이값 중 상위 K개만을 포함하고 나머지는 0으로 대체되면서 차원이 축소되며 이를 절단된 특이값 분해라 한다. 이를 통해 행렬 R의 주요한 패턴만을 활용할 수 있고, 하위 특이값을 계산에서 제외함으로써 계산의 복잡도를 감소시킬 수 있으며, 중요하지 않은 패턴과 잡음(noise)을 제거할 수 있다. 이러한 과정을 거쳐 행렬 R을 수식(4)와 같이 근사화시킬 수 있다.
이를 통해 계산된 행렬 을 바탕으로 사용자의 선호도의 예측치를 계산할 수 있다. 구체적으로 사용자 u의 항목 i에 대한 선호도 예측치 는 수식(5)와 같이 정의된다.
이때, k는 특이값의 개수, wuk와 vik는 각각 사용자 u와 항목 i의 잠재 요인을 나타낸다. 선호도 예측치는 항목에 대한 사용자의 예상되는 선호도로 이를 바탕으로 특정 사용자에 대한 추천 항목이 생성된다. 이러한 과정을 통해 특이값 분해는 데이터의 희소성을 해결하고, 계산 복잡도를 줄이면서도 좋은 추천 정확도를 제공하는 강력한 추천 방법으로 다양한 연구에서 활용되고 있다(Lu et al., 2012).
하이브리드 추천 시스템의 알고리즘은 시스템의 목적이나, 활용되는 모델과 결합 방식 등에 따라 매우 다양한 방식이 존재한다(Cai et al., 2021). 본 연구에서는 앞서 언급한 특이값 분해 기반 협업 필터링 모델과 콘텐츠 기반 필터링을 결합하여 콜드 스타트 문제를 완화시키고자 하며, 메모리기반 협업 필터링의 방법들은 비교모델로 활용한다.
콘텐츠 기반 필터링은 사용자가 이전에 선호한 항목과 유사한 항목을 찾아 추천하는 방식이다. 유사한 항목을 찾기 위하여 항목의 특성을 기반으로 유사도의 계산이 필요하다. 이를 위해 문자 정보인 항목 특성을 수리적으로 계산하기 위해 원-핫 인코딩(one-hot-encoding) 등의 방식으로 벡터화(vectorization)한다. 벡터화된 항목 특성을 활용하여 사용자가 선호한 항목과 다른 항목 간의 유사도를 아래 수식(6)과 같이 계산하여 사용자 u의 항목 i에 대한 선호도 를 도출할 수 있다.
Ru,j는 사용자 u의 항목 j에 대한 선호도이며, sim(i,j)는 항목 i와 항목 j 간의 유사도, N(i)는 항목 i와 유사도가 가장 높은 N개의 항목 집합을 의미한다.
콘텐츠 기반 필터링을 통해 도출된 유사도와 특이값 분해 기반 협업 필터링에서 도출된 예측 선호도에 가중치를 부여하여 하이브리드 추천 시스템의 최종 선호도를 계산하는 결합 방식을 활용하였으며, 가중치를 결합하는 계산 방법은 수식(7)과 같다.
이때 α는 가중치를 의미하며 0~1 사이의 값을 가지며, 계산된 선호도를 바탕으로 최종 추천 항목이 생성된다. 이처럼 협업 필터링으로 예측된 선호도에 콘텐츠 기반 필터링을 통해 산출된 유사도를 결합하는 간단한 하이브리드 방식으로도 추천 시스템의 성능을 향상시킬 수 있다(McNee, 2006).
추천 시스템은 가장 높은 선호도를 보이는 상위 N개의 항목을 추천하거나 선호도를 평점으로 변환하여 제시하기도 하며, 약간의 과정을 거쳐 예상되는 구매량으로 변환하여 보여줄 수 있다.
사용자 유사도 기반의 추천 시스템은 앞서 언급한 것과 같이 가장 유사한 사용자의 선택을 기반으로 최종 추천 항목이 선택된다. 이때 상위 유사 사용자들이 선택한 항목들의 평균 선호도 또는 평균 구매량을 통해 수량의 추천이 가능하다. 예를 들어 상위 5명의 사용자가 가장 많이 선택한 상품 5개를 추천 항목으로 제시되며, 이때 상위 사용자들의 상품별 평균 구매량을 추천 수량으로 제시할 수 있다.
특이값 분해 기반 추천 시스템의 경우 사용자-항목 행렬 R을 행렬 분해하여 근사 행렬 R ̃을 계산한다. 계산된 근사 행렬의 요소는 사용자와 항목 간 잠재적인 관계를 반영하는 값이며, 이는 사용자의 예측된 선호도 또는 구매 수량을 나타내 이를 기반으로 수량의 추천을 수행할 수 있다.
추천 시스템의 평가는 완성된 추천 시스템 실제로 적용해보고 적용하기 전과 후를 비교하는 것이 바람직하지만, 일반적으로는 추천 시스템의 구성을 위해 활용하는 데이터를 훈련 데이터와 검증 데이터로 구분하여, 검증자료를 활용하여 평가하게 된다. 추천 시스템의 평가는 학습 데이터를 통해 생성된 추천 항목을 검증 데이터와 비교를 통해 이루어지며, 성능을 평가하는 방법은 추천 시스템이 달성하고자 하는 목표에 따라 달라질 수 있다.
다양한 성능 평가 방법 중 분류 지표(classification metrics)는 사용자가 어떤 항목을 선호했는지 알 수 있는 상황에서 활용된다. 즉, 추천 목록의 상위 K개와 검증 데이터와 비교하여 실제 사용자가 선호하는 항목이 얼마나 포함되었는지를 고려하는 것이다.
이와 관련하여 가장 많이 활용되는 지표는 정밀도(precision)와 재현율(recall)이다. 정밀도와 재현율은 크게 두 가지로 구분할 수 있는데 모든 항목에 대해서 정밀도와 재현율은 포괄적으로 계산하는 방법을 마이크로(micro) 정밀도 및 재현율이라고 하며, 개별적인 항목의 정확도와 재현율을 평가하여 항목 간 정확도 차이를 고려할 수 있는 매크로(macro) 정밀도 및 재현율이라고 한다. 먼저 마이크로 정밀도 및 재현율은 수식(8)과 같이 정의할 수 있다.
-
TP: 추천 시스템이 선호(positive)로 예측했고, 실제 사용자가 선호하는 경우
-
FP: 추천 시스템이 선호로 예측하였으나, 실제 사용자가 선호하지 않는 경우(negative)
-
FN: 추천 시스템이 불호로 예측하였으나, 실제 사용자는 선호하는 경우
정밀도가 높다는 것은 사용자가 실제로 선호하는 것을 정확하게 예측했다는 것을 의미하며, 재현율이 높다는 것은 사용자가 실제로 선호하는 것을 놓치지 않았다는 것을 의미한다. 즉, 정밀도는 잘못된 긍정(FP)의 최소화, 재현율은 놓친 긍정(FN)의 최소화가 목적이다. 정밀도를 높이기 위해서는 추천하는 항목의 수가 낮아지는 것이 유리하지만, 반대로 재현율을 높이기 위해서는 추천하는 항목의 수가 높아지는 것이 유리하기에, 두 개의 기준을 모두 충족시키는 것은 쉬운 일이 아니다.
이처럼 추천되는 항목의 수에 따라 지표가 영향을 받기 때문에 이를 최소화하기 위한 지표로 F1-점수(score)를 활용할 수 있다. F1-점수는 정밀도와 재현율을 결합한 지표로 수식(9)와 같이 정의된다.
이러한 방식은 항목의 불균형을 고려하지 않고 전반적인 성능을 평가하게 된다.
만약 특정 항목의 정밀도나 재현율이 과도하게 낮아 불균형이 존재할 경우 추천 시스템의 성능에 대한 정확한 평가가 불가능하다. 이를 방지하기 위해 개별적인 항목의 정확도와 재현율을 평가하여 항목 간 정확도 차이를 고려할 수 있는 매크로(macro) 정밀도 및 재현율, F1 지표를 사용할 수 있으며, 이는 수식(10)과 같다.
매크로 정밀도 및 재현율 지표는 모든 항목에 대해 동일한 중요도를 가지기 때문에 불균형이 존재할 경우 이에 대한 영향을 마이크로 정밀도 및 재현율보다 높게 반영할 수 있다는 장점을 가지고 있다. 다만 항목의 수가 적은 경우 개별 항목의 정확도가 전반적인 추천 시스템의 성능 평가에 과도하게 반영될 수 있다는 단점을 가지고 있다.
추천 시스템에서는 항목에 대한 추천뿐만이 아니라 항목에 대한 선호도나 구매 수량 등의 정량적인 평가도 생성된다. 예를 들어 사용자가 선호할 것으로 예상되는 영화의 추천은 이에 대한 예측 평점을 통해 판단될 수 있다. 이러한 항목의 정량적인 평가 또한 추천 시스템 성능을 판단할 수 있는 기준이 되며 이를 위해 주로 평균 제곱근 오차(root mean squared error)가 활용되며 수식(11)과 같이 정의할 수 있다.
해당 지표들은 예측값과 실제값의 오차를 정량화하며, 오차가 작을수록 추천 시스템의 정확도가 높음을 의미한다.
Ⅲ. 연구방법
연구에 사용한 자료는 포항 중소유통공동도매물류센터의 2021~2023년 거래 데이터를 활용하였다. 중소유통공동도매물류센터는 산업통상자원부의 풀필먼트 구축 사업을 통해 설립된 것으로 지역 내 소매점의 판매지원을 위해 운영되고 있다. 3년간 중소유통공동도매물류센터에서 구매를 진행한 소매점의 수는 293개이며, 거래 건수는 2021년 351,197건, 2022년 350,844건, 2023년 336,017건으로 전체 1,038,058건이다. 각 거래 내역에는 구분(매출 또는 반품), 판매수량, 옵션코드(낱개, 소량 묶음, 박스), 상품 바코드, 상품명, 공급가격 등이 포함되어 있다.
전체 자료를 모두 분석에 적용하기 전에 사전 처리 작업을 진행하였다. 전체 거래 내역의 상품 바코드와 대한상공회의소 유통물류진흥원의 유통표준코드와 대조하여 바코드의 정확성을 판단하였다. 거래 내역의 상품 바코드는 유통업체에서 편의성의 이유로 자체 상품 바코드를 사용하는 등으로 인해 대한상공회의소의 표준 상품 바코드와 일치하지 않은 경우가 존재하였다. 상품명이 표준화되어있지 않아 상품 바코드로 항목을 구분해야 하는 상황에서 표준 바코드와 거래내역의 상품 바코드가 상이한 경우 A라는 상품에 다수의 서로 다른 상품 바코드가 존재할 수 있다. 이는 분석 결과의 정확성에 영향을 미치기 때문에 표준 상품 바코드와 매칭되지 않는 상품 바코드의 거래내역 516,500건은 분석에서 제외하였다.
중소유통공동도매물류센터에서 상품을 거래 시 반품된 경우가 존재하여 이에 대한 처리를 다음과 같이 진행하였다. 반품 거래가 발생한 날짜를 기준으로 60일 이전에 동일한 유통업체 및 상품의 매출 거래가 발생하였는지 확인하였다. 반품 거래 내역과 일치하는 매출 거래가 존재할 경우 (1) 두 거래 내역의 구매액이 일치하면 매출과 반품 거래내역 모두 삭제, (2) 반품 거래 내역의 구매액이 매출 거래 내역보다 클 경우 매출과 반품 거래내역 모두 삭제, (3) 매출 거래 내역의 구매액이 클 경우 반품 거래 내역은 삭제하고 매출 거래 내역의 구매액에서 반품 거래액을 차감, (4) 반품 거래 내역만 존재할 경우 해당 거래 내역만 삭제하였다. 이 과정을 통해 20,598개의 거래내역을 삭제하였으며 반품 관련 내역이 삭제되었다. 최종적으로 287개 소매점이 거래한 5,137개 상품에 대한 495,902건의 거래 내역이 분석에 사용되었다.
다음으로 항목 구성 시 낱개, 소량 묶음, 박스 등의 구매 옵션을 바탕으로 상품 개수의 표준화를 진행하였다. A 상품을 구매 시 낱개로 1단위를 구매하는 것과 박스로 1단위를 구매하는 것의 실질적인 수량이 다르기 때문이다. 따라서 소량 묶음과 박스 단위로 구매된 상품의 경우 수량을 낱개로 표준화하였다. 데이터 사전 처리 과정의 마지막으로 학습과 검증 데이터의 분리를 진행하였다.
학습 데이터는 2021년 및 2022년 데이터를 활용하였으며, 검증 데이터는 2023년 데이터를 활용하였다. 추천을 수행하는 기간은 한 달을 기준으로 구매가 예상되는 항목의 추천을 진행하였다. 학습 데이터는 추천을 수행하는 월을 포함한 이전 3개월의 과거 거래 내역으로 구성하였다. 예를 들어 2023년 5월 기준의 상품을 추천하는 경우 2021년 및 2022년 3월, 4월, 5월의 데이터가 학습 데이터로 활용되며, 이는 추천을 수행하는 기간에 따라서 조정되도록 구성하였다. 이와 같은 방식으로 학습 데이터를 구성한 이유는 분석기간 3년 동안 거래가 중단되거나 새롭게 거래를 시작하는 소매점이 존재하였으며, 소매점이 구매하는 상품 및 수량이 계절에 따라 상이한 모습을 보였기 때문이다. 이로 인해 구매 시점 이전의 거래내역을 모두 학습 데이터로 반영하는 것은 오히려 추천의 정확도를 감소시키는 원인으로 작용하여 추천 수행 기준 날짜에 따라 학습 데이터를 조정하는 방식으로 추천 시스템을 구축하였다.
추천을 수행하는 기간을 기준으로 분리된 학습 데이터를 바탕으로 소매점별 상품 구매 수의 평균을 행렬 요소로 하는 소매점-상품 행렬을 구성하여 추천 알고리즘에 적용하였다. 이때, 행렬을 구성하는 사용자 및 상품은 전체 기간을 대상으로 구성하고 추천 수행 기간에 따라 행렬 요소만이 변경될 수 있도록 알고리즘을 구성하였다. 즉, 287개 소매점과 5,137개 상품으로 구성된 행렬은 고정되어 있고, 기간에 따라 소매점별 구매한 상품의 평균 개수만이 조정되는 형태이다. 추천 시스템의 성능 평가 시 같은 조건에서 평가될 수 있도록 행렬 구조의 일관성을 유지하였다(Takama et al., 2020).
본 연구에서는 특이값 분해 기반의 협업 필터링 추천 시스템을 활용하여 중소유통공동도매물류센터를 이용하는 소매점의 향후 구매할 상품과 수량을 예측하였으며, 전체 모델은 <그림 1>과 같다. 특이값 분해 기반 협업 필터링 추천 시스템은 완전 특이값 분해와 절단된 특이값 분해 모델을 활용하였고, 성능의 비교를 위해 메모리 기반 유사도 협업 필터링 추천 시스템을 구축하였으며, 협업 필터링 추천 시스템의 단점인 콜드 스타트 문제를 개선하기 위해 콘텐츠 기반 필터링을 결합한 하이브리드 추천 시스템을 구축하여 추천 시스템 간 성능을 비교하였다.
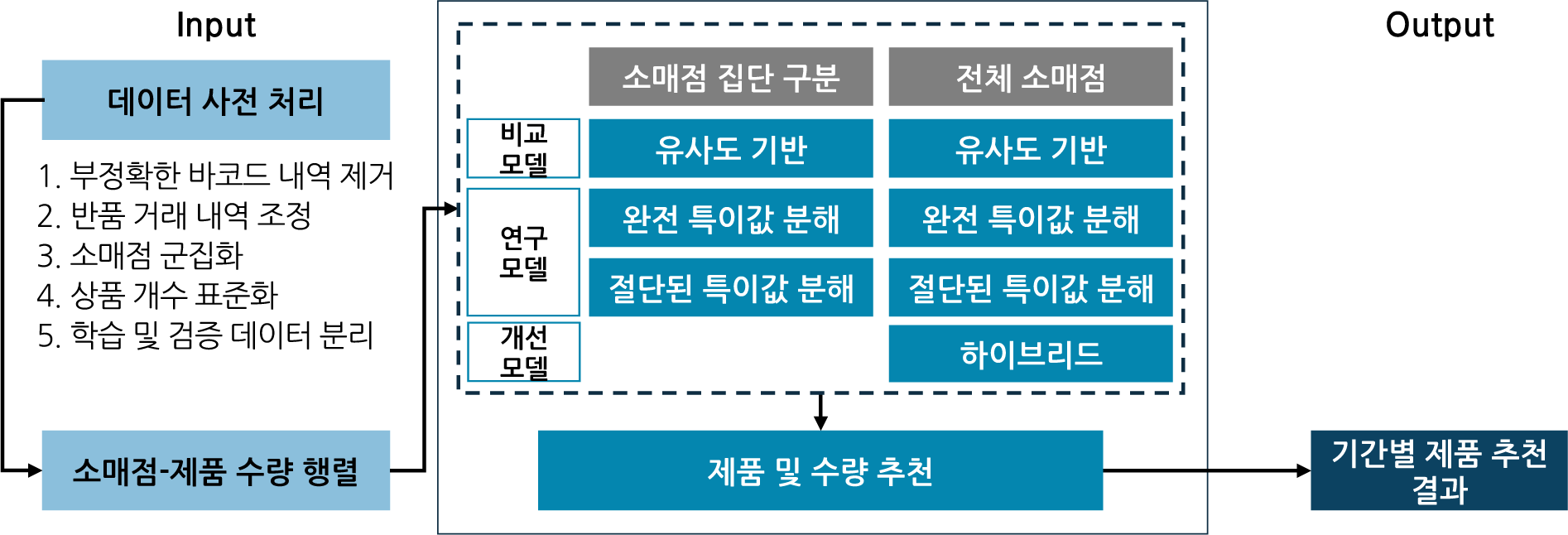
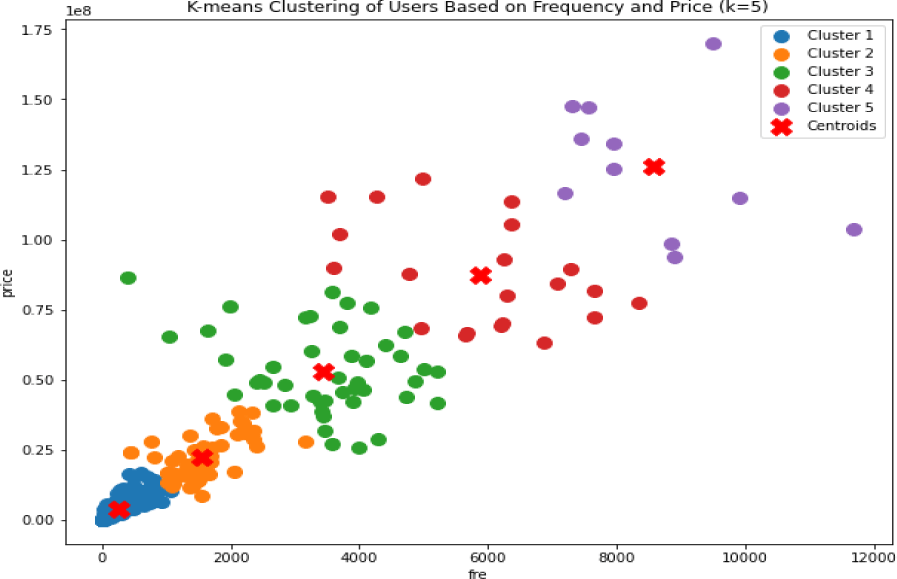
소매점-상품 행렬의 구성 전에 데이터 전처리를 진행하였다. 먼저 소매점의 특성에 따라 자주 구매하는 상품의 종류와 수량이 다를 수 있어 구매 빈도와 구매액을 바탕으로 군집화를 실시하였다. 군집화를 위해 거래 빈도 및 거래액의 표준화를 진행하였으며, 표준화된 데이터에 K-means 알고리즘을 적용하여 군집을 형성하였다. <그림 2>와 같이 5개의 군집으로 구분하였으며, 군집 1은 156개, 군집 2는 54개, 군집 3은 45개, 군집 4는 21개, 군집 5는 11개로 나타났다. 군집 분석 결과를 추천 알고리즘에 적용해 동일 군집별로 추천모델을 적용하였으며, 군집 분석 결과로 추천모델을 적용하는 것의 효과를 분석하기 위하여 전체 소매점을 대상으로도 추천 모델을 적용하였다.
추천 알고리즘 간의 성능 비교를 위하여 유사도 기반, 완전 특이값 분해 및 절단된 특이값 분해, 하이브리드 모델을 사용하여 추천을 진행하였다.
유사도 기반 알고리즘에서는 소매점-상품 행렬을 기반으로 사용자 간의 코사인 유사도를 계산하고 가장 유사한 5개의 소매점을 선택하게 된다. 유사 소매점 개수는 가장 유사한 소매점 1개만을 선택하는 것부터 군집 분석 결과 최소 군집 크기인 11개까지 투입하여 분석한 결과 가장 유사한 소매점 5개를 바탕으로 추천을 생성할 때 정확도가 가장 높아 이를 활용하였다. 성능의 비교를 위해 군집 적용 및 미적용 모델 모두 유사도가 가장 높은 소매점 5개를 선택하여 평균 구매 수량을 바탕으로 상품 및 구매 수량을 추천하였다. 이때, 추천되는 상품은 추천 구매 수량이 1 이상인 상품 전체가 대상이 되었다.
완전 특이값 분해 및 절단된 특이값 분해 기반 알고리즘에서는 유사도 기반 알고리즘과 동일하게 먼저 소매점-상품 행렬을 구성하고 이를 행렬 분해하여 추천 상품을 도출하였다. 이때, 절단된 특이값 분해의 경우 축소되는 차원의 수는 100부터 시작하여 100단위씩 증가시키며 결과를 비교한 결과 전반적으로 차원 수 500에서 가장 좋은 결과가 나타나 이를 모델에 적용하였다. 분해된 행렬을 바탕으로 구매 예측 행렬을 생성하여 소매점별 구매가 예상되는 상품 및 수량을 추천하였다. 유사도 기반과 동일하게 최종적으로 추천되는 상품은 임계값이 1 이상인 상품만이 추천 대상이 되었다.
마지막으로 구축된 특이값 분해 기반 협업 필터링 모델에 콘텐츠 기반 필터링 모델을 결합하여 하이브리드 추천 시스템을 구축하였다. 콘텐츠 기반 필터링 모델에서 식품, 가전제품 등으로 구분된 대분류와 이를 더 상세하게 분류한 중분류 및 소분류를 상품의 특성을 원-핫 인코딩을 통해 벡터화 하였다. 이를 바탕으로 소매점 프로필을 생성하고 상품 간의 유사도를 계산하여 선호도를 도출하였다. 이를 협업 필터링을 통해 산출된 선호도와 결합하여 최종적으로 추천 항목을 예측하였으며, 이때 가중치는 가장 높은 정확도를 보인 0.5를 활용하였다. 추천되는 항목의 개수는 이전 알고리즘과 동일한 방식을 활용하였다.
이를 종합하면 소매점 대상 상품 추천을 위하여 소매점 군집 분석 결과(적용 vs 미적용), 추천 알고리즘(유사도 기반 vs 완전 특이값 분해 vs 절단된 특이값 분해 vs 하이브리드 모델)에 따라 <그림 3>과 같이 총 8개 모델을 구성하고 추천 결과를 도출하여 각 모델의 성능을 비교하였다.

추천 시스템의 성능 비교를 위한 평가지표로 추천된 상품의 정확도를 측정하기 위해 마이크로 정밀도 및 재현율, 매크로 정밀도 및 재현율을 활용하였으며, 추천된 항목의 수량에 대한 정확도 측정을 위하여 평균 제곱근 오차를 활용하였다.
Ⅳ. 모델 적용 및 결과
<표 1>은 6개 추천 모델에 대한 정확도 평가 결과이다. 소매점이 향후 구매할 상품을 얼마나 정확하게 추천했는지 평가하는 매크로 및 마이크로 정밀도, 재현율, F1-점수가 가장 높은 모델은 소매점을 군집화하지 않고 전체를 대상으로 추천 상품을 예측한 절단된 특이값 분해 모델로 나타났다. 특이값 분해 기반 협업 필터링은 추천 대상이 되는 소매점과 유사한 소매점을 바탕으로 추천이 수행되는 것이 아니라 전체 소매점과 상품 간 상호작용의 잠재요인을 바탕으로 추천이 수행된다. 따라서 과거에 소매점이 구매했던 상품 이외에도 이와 유사한 특징을 가진 다른 상품까지 추천할 수 있다. 또한 특정소매점이 모든 상품을 골고루 구매하는 것이 아니기에 나타날 수밖에 없는 희소성 문제는 특이값 분해 모델을 통해 완화시킬 수 있기 때문에 정확도가 상대적으로 높게 나타난 것으로 보인다.
상품의 수량의 정확도를 측정하는 평균 제곱근 오차가 가장 낮은 모델은 소매점을 군집화하여 추천 상품을 예측한 유사도 기반 모델로 나타났다. 유사도 기반 협업 필터링 모델은 향후 구매가 예상되는 항목의 정확성은 특이값 분해 기반 모델과 비교했을 때 다소 낮은 것으로 나타났다. 소매점의 유사도를 기반으로 상품을 추천할 경우 새로운 상품의 추천은 거의 이루어지지 않고 과거에 많이 구매했던 상품만을 대상으로 추천이 이루어지기 때문에 편향이 발생하여 정확도가 낮아질 수 있다(Zanon et al., 2022). 반면, 상품 수량에 대한 추천의 경우 특이값 분해 모델에 비해 더 정확한 것으로 나타났다. 이는 모델에서 구매한 상품만이 아니라 수량의 유사도가 높은 소매점을 찾아 이를 바탕으로 추천을 수행하기에 추천 대상이 되는 소매점과 비슷한 수량을 거래하는 소매점만이 학습되어 추천이 수행되기 때문에 수량의 정확도가 높아질 수 있다.
협업 필터링 추천 모델에 군집화를 적용할 경우 유사한 집단 내에서만 추천을 수행하기 때문에 추천되는 항목의 다양성이 감소할 수 있으며, 특정 군집 내에서는 학습에 필요한 정보가 부족할 수 있다(Al-Ghuribi et al., 2023). 즉, 특정 소매점 집단 내에서 구매가 가장 많이 발생한 상품이 추천되기 때문에 추천되는 상품이 한정되어 새로운 상품 추천에 한계가 존재하여 추천의 정확도가 감소할 수 있다. 또 소매점을 군집화한 기준은 거래 빈도와 거래액으로 거래 빈도가 낮은 집단에서는 소매점의 특성을 충분히 학습할 수 있는 정보가 부족하여 추천 정확도가 감소한 것으로 보인다. 한편, 군집화를 적용하면 유사한 선호도를 가진 사용자를 대상으로 유사도가 계산되기 때문에 추천 품질이 향상될 수 있다(Al-Ghuribi et al., 2023). 따라서 군집화를 적용한 추천 모델에서는 소매점별 상품의 구매 수량 추천에 대한 정확도가 높았으며 특히 유사도를 기반으로 추천 수량을 예측했을 때 더욱 높게 나타났다.
<표 2>는 절단된 특이값 분해 기반 협업 필터링과 콘텐츠 기반 필터링을 결합한 하이브리드 추천 모델에 대한 정확도 평가 결과이다. 협업 필터링 단독 모델의 성능과 비교했을 때, 하이브리드 모델을 활용할 경우 소매점 집단을 구분한 상황에서 마이크로 관련 지표 및 평균 제곱근 오차가 개선되었으며, 집단을 구분하지 않은 상황에서는 정밀도 및 평균 제곱근 오차가 개선되었다. 이는 협업 필터링 기반 추천 시스템의 한계점인 콜드 스타트 문제가 개선되어 나타난 결과로 보인다. 특히, 본 연구에서 활용한 모델은 추천 기간을 기준으로 과거 자료 중 일부를 추출하여 학습 데이터로 활용했기 때문에 콜드 스타트 문제가 더욱 부각되었을 가능성이 높다. 그러나 재현율은 다소 감소한 모습을 보였다. 재현율은 추천 항목의 다양성이 늘어날수록 증가하는데, 콘텐츠 기반 필터링이 결합되면서 추천되는 상품의 다양성이 다소 감소하였기에 나타난 결과로 보인다.
추가적으로 계절 및 소매점 집단별 추천 시스템의 정확도를 평가하였으며, 결과는 <표 3>에서 확인할 수 있다. 계절에 따른 상품 추천의 정확도는 큰 차이는 나타나지 않았으나 상대적으로 가을(9월~11월)이 가장 높았으며, 여름(6월~8월)이 가장 낮았다. 반대로 상품 수량 추천의 정확도는 가을이 가장 낮았으며, 봄(3월~5월)이 가장 높게 나타났다.
소매점 집단별 추천 정확도는 2~5번 집단은 거의 차이가 나타나지 않았으나, 1번 집단의 추천 정확도는 매우 낮게 나타났다. 1번 집단은 전체 287개 소매점 중 156개 소매점이 속한 집단으로 구매 빈도와 구매액이 가장 작은 특성을 가지고 있다. 1번 집단의 3년간 구매 빈도는 39,187회이나, 가장 적은 소매점이 속한 3번 집단(11개)의 동기간 구매 빈도는 94,274회로 나타났다. 이로 인하여 정확한 구매 패턴의 파악이 어려워 추천의 정확도가 매우 낮게 나타났다고 볼 수 있다. SVD 기반의 추천 시스템은 데이터가 희소한 경우에도 효과적인 추천이 가능하지만 결측값이 과도하게 존재하는 경우에는 정확한 추천이 어려울 수 있다(Koren et al., 2009).
이에 더해 추천된 상품과 실제 거래된 상품과의 차이를 파악하기 위해 Model 7의 결과를 살펴보았다. 전체 상품 중 거래량이 많은 상위 20개 상품을 확인한 결과 <그림 4>에서처럼 전반적으로 실제 상품의 거래량보다 상품의 추천 수량이 다소 낮은 모습을 보이고 있다. 특히 그래프에서도 확인할 수 있듯이 여름(6월~8월)에 실제 거래량과 추천 수량의 차이가 크게 나타나 전반적으로 상품별 거래량을 확인하였다. 그 결과 여름에 생수 및 라면의 급격한 거래량 증가를 추천 시스템에서 정확히 반영되지 않은 것으로 보인다. 이처럼 생수나 라면 등 거래량이 급증하는 상품이 있는 반면, 급감하는 상품이 존재하여 단순히 거래 데이터만으로 파악할 수 없는 변동 원인이 존재할 것으로 예상된다.
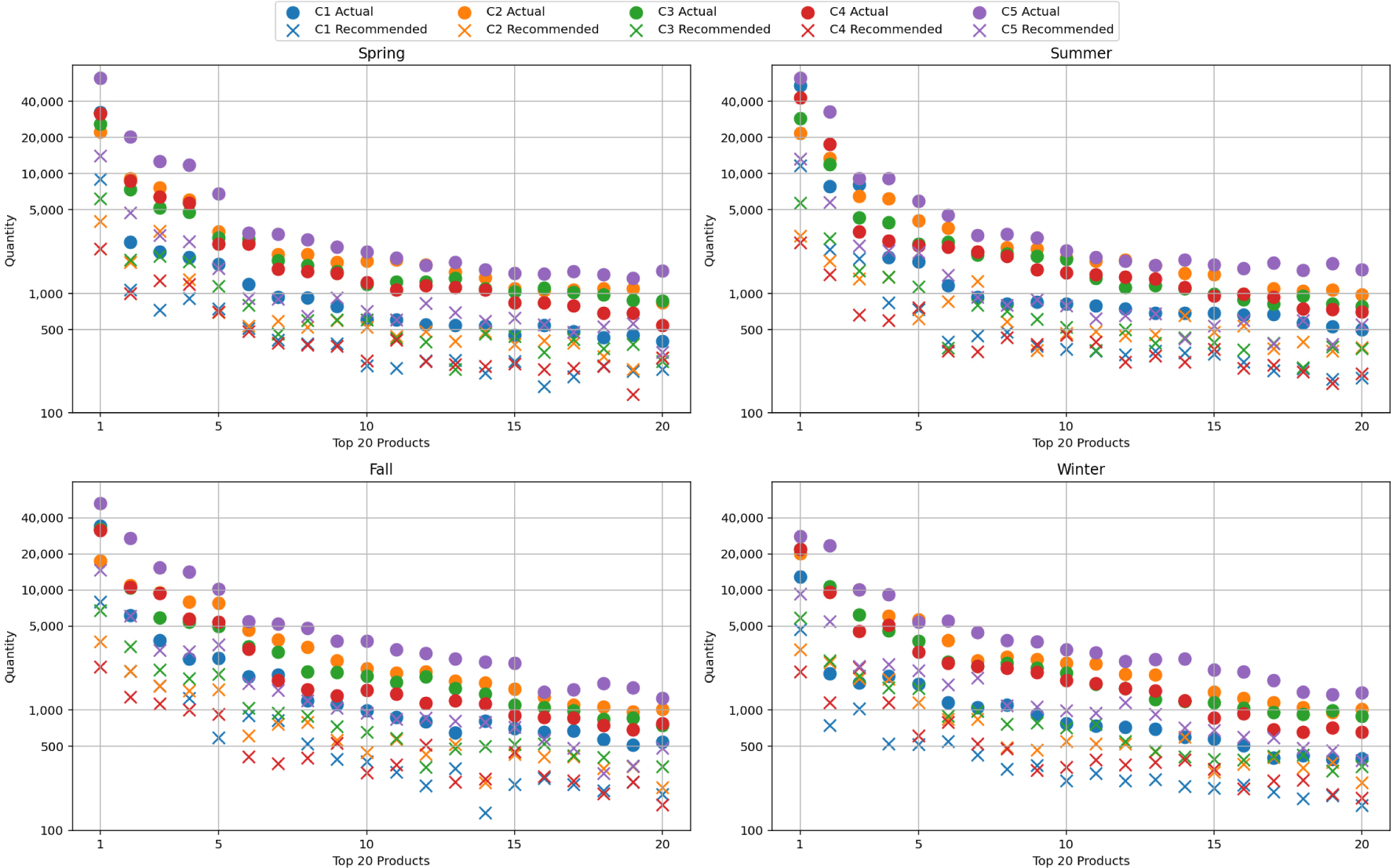
소매점 집단에 따른 상품별 거래량을 확인한 결과 전반적인 상품 거래량의 차이가 나타났으며, <표 4>의 계절별 및 소매점 집단별 상위 구매수량 상품명 3개와 같이 집단에 따라 상위 구매 상품의 차이는 거의 보이지 않았다.
Ⅴ. 결론 및 논의
B2B 유통 분야에서 추천 시스템에 대한 연구는 환경의 복잡성과 거래 정보 확보의 어려움 등으로 매우 제한적이었다. 이에 본 연구에서는 중소유통공동도매물류센터의 실제 거래 데이터를 활용하여 협업 필터링 기반의 추천 시스템을 구축하고 모델별 성능 비교를 진행하였다.
완전 및 절단된 특이값 분해 기반 협업 필터링 모델은 유사도 기반 협업 필터링 모델에 비해 상대적으로 구매 상품에 대한 정확도가 높은 것으로 나타났다. 이는 특이값 분해 기반 협업 필터링이 소매점-상품 상호작용의 잠재 요인을 학습하여 추천을 수행하기 때문에 과거에 구매하지 않은 새로운 상품에 대한 추천이 가능하고, 거래 데이터에서 나타날 수 있는 희소성 문제를 효과적으로 완화시킬 수 있어 나타난 결과로 보인다.
반면 유사도 기반 협업 필터링의 경우 추천된 상품에 대한 정확도는 특이값 분해 기반 모델에 비해 상대적으로 낮게 나타났으나, 수량 추천 정확도는 높게 나타났다. 이는 구매한 상품뿐만 아니라 수량도 비슷한 소매점의 정보를 바탕으로 추천이 수행되기 때문에 정확도가 더 높은 것으로 보인다.
협업 필터링 추천 모델에 군집화를 적용한 결과 상품 추천의 정확도는 감소하였으며, 수량 추천의 정확도는 높아진 것으로 나타났다. 이는 비슷한 소매점 집단을 분류하고, 집단별로 추천을 수행했기 때문에 나타난 결과로 볼 수 있다. 구매 빈도와 금액이 비슷한 집단 내에서 구매된 상품과 수량이 학습되어 추천이 수행되었기 때문에 학습 데이터의 부족이나 추천되는 상품 종류의 한계 등으로 상품 추천에 대한 정확도는 감소할 수 있으나, 수량에 대한 추천은 오히려 더 정확해질 수 있다.
협업 필터링과 콘텐츠 기반 필터링을 결합한 하이브리드 모델은 협업 필터링 모델을 단독으로 사용한 것보다 상품과 수량 추천 정확도 모두 향상된 모습을 보였다. 이는 협업 필터링 모델의 한계점으로 작용하는 콜드 스타트 문제가 완화됨으로써 나타난 결과이다.
계절별·소매점 집단별 추천 정확도를 추가 분석한 결과 상대적으로 상품 추천의 정확도는 가을이 가장 높고, 여름이 가장 낮았으며, 상품 수량의 정확도는 봄이 가장 높고, 가을이 가장 낮게 나타났다. 거래 데이터의 희소성으로 인한 한계를 극복하기 위해 SVD 기반의 추천 시스템을 활용하였으나 극도로 희소한 데이터의 경우 적용에 한계가 있음을 확인하였다.
본 연구의 이론적 시사점은 다음과 같다. 첫째, B2B 유통 분야에서 추천 시스템의 적용 가능성을 확인하였다. B2B 유통 분야는 데이터 희소성, 거래의 복잡성, 정보 비대칭 등의 제약으로 추천 시스템 적용이 어렵지만, 적절한 모델링을 통해 정보 과부하 문제를 해결하고 의사결정을 지원할 수 있음을 연구를 통해 확인하였다. 특히, 특이값 분해 기반의 협업 필터링 모델은 기존 구매 데이터뿐만 아니라 새로운 상품 추천이 가능하며, 거래 데이터의 희소성을 완화하는 데 유리하다는 점에서 B2C 분야뿐만 아니라 B2B 환경에서도 적용할 수 있음을 보여주고 있다.
둘째, 추천 모델에 따라 추천 항목과 수량의 정확도의 차이가 나타나는 것을 밝혔다. 특이값 분해 기반 모델은 추천 항목의 다양성과 정확도를 높이는 데 효과적이며, 유사도 기반 모델은 수량 예측의 정확도가 더 높은 결과를 보였다. 또한 소매점 군집화를 활용한 추천 모델의 경우 상품 추천 정확도는 다소 감소하지만, 수량 추천 정확도가 더욱 높아지는 것을 확인하였다. 이는 추천 시스템의 목적과 데이터 특성에 따라 최적의 접근 방식을 선택해야 함을 시사하고 있다.
셋째, 하이브리드 모델을 통한 성능 개선 가능성을 보여주고 있다. 본 연구에서는 협업 필터링과 콘텐츠 기반 필터링을 결합한 하이브리드 모델은 콜드 스타트 문제를 효과적으로 완화하고 추천 정확도를 개선하였다. 이는 전통적인 협업 필터링의 한계를 보완하고 다양한 데이터를 활용한 모델링이 B2B 유통 분야에서도 실질적인 성능 개선으로 이어질 수 있었다. 특히, 추천 시스템을 통해 도출된 선호도를 결합하는 간단한 하이브리드 모델로도 성능 개선이 가능하다는 것을 확인하였다.
본 연구의 실무적 시사점은 다음과 같다. 첫째, 소매점의 판매 기회 확장을 제안하여 신규 수요를 창출 할 수 있다. 경험이 부족하거나 정보 획득이 어려운 소매점의 경우 도매상의 제안 또는 과거 구매 이력에 의존하여 유사한 상품 구색만을 취급할 가능성이 높다. 그러나 추천 시스템을 활용할 경우 소매점은 인지하지 못한 상품에 접근하여 구색 확장에 도움을 줄 수 있다.
둘째, 수요 예측의 정확도 향상을 통해 재고 관리, 발주 계획 수립 등에 실질적인 도움을 줄 수 있다. 자사와 유사한 다른 소매점의 판매를 기반으로 상품이 추천되는 것을 활용하여 인기 상품을 빠르게 확보하거나 불필요한 상품의 구매를 축소할 수 있으며, 구매 의사결정에 대한 노력을 감소시키는 등의 역할이 가능하다. 마찬가지로 도매점 또한 추천 시스템을 통한 재고 관리를 통해 과잉 재고를 방지할 수 있다.
셋째, 콜드 스타트를 극복한 추천 시스템을 활용할 경우 소매점 및 도매점에 이점을 가져올 수 있다. 신규 소매점일 유사 매장의 운영 데이터 기반의 추천을 바탕으로 초기 상품 구색 설계가 용이할 수 있으며, 도매점의 경우 추천 상품 리스트를 바탕으로 신규 거래처 확대에 이점이 존재한다.
본 연구의 한계점 및 향후 연구방안은 다음과 같다. 첫째, 활용된 중소유통공동도매물류센터의 거래 내역은 대한상공회의소 유통물류진흥원에 등록되어 있는 유통표준코드와 일치하는 내역만을 활용했기 때문에 전체 거래 내역 중 약 50% 정도만을 활용하였다. 특히 일부 소매점의 경우 자체 상품 바코드를 사용하는 비중이 80%가 넘는 경우가 존재해 정확한 구매 행동 파악에 한계가 존재했다. 실제 유통 거래 데이터를 활용하는 연구에서 정확하고 충분한 기초 자료 확보 등의 학술적인 측면뿐만 아니라 물류 및 재고 관리의 효율성, 상품 이력 관리 등 실무적인 측면에서도 향후 제조사, 상품 분류, 상품명 등 상품의 정보를 바탕으로 정확한 유통표준코드를 할당할 수 있는 연구가 필요할 것으로 보인다.
둘째, 추천 시스템의 구축을 위해 특이값 분해 기반의 협업 필터링 모델을 중점적으로 활용하였다. 그러나 최근에는 추천의 정확도를 높이고 데이터의 희소성, 콜드 스타트 등의 문제를 해결하기 위해 상품, 구매자 및 판매자 정보 등 다양한 정보를 투입하고, 신경망 또는 강화 학습 등 딥러닝 알고리즘을 활용한 추천 모델 연구가 진행되고 있다. 본 연구에서는 비교적 전통적인 방법의 추천 모델만을 활용하였기 때문에 구입 시기, 상품 가격 및 카테고리, 소매점이 위치한 상권 정보 등 부가적인 정보를 모델에 완벽하게 반영하지 못하였다. 향후 다양한 부가 정보를 반영할 수 있는 추천 모델에 대한 연구가 진행된다면 추천 시스템의 성능의 개선과 더불어 현장에 적용할 수 있는 가능성이 높아질 것이라 생각된다.
셋째, 본 연구에서는 상품 추천뿐만 아니라 수량까지 추천을 수행하였으나, 추천된 구매 수량이 실제 구매 수량보다 현저히 낮게 도출되는 경향이 나타났다. 이는 기존의 상품 추천 알고리즘을 변형하여 수량 추천에 적용한 결과로 해석된다. 즉, 상품 추천의 적합도를 기준으로 수량을 도출하는 방식은 실제 수요를 정확하게 반영하는 데 한계가 존재할 수 있다. 따라서 향후 연구에서는 수량 추천의 정확도를 높이기 위한 별도의 방법론 개발이 필요하며, 특히 수요 예측 모델이나 시계열 기반 접근, 클러스터별 수량 추정 보정 등 실질적인 수요 예측 관점에서의 연구가 병행되어야 할 것이다.
마지막으로, 추천 시스템의 성능을 평가하기 위해 정밀도, 재현율, F1-점수, RMSE만을 사용하였으며, 신뢰성(trustworthiness)이나 다양성(diversity) 등 추천 시스템의 성능을 보다 다양하게 평가할 수 있는 지표는 활용하지 않았다. 신뢰성은 실제 소매점의 의사결정자가 추천 결과를 받아들이고 구매 행동으로 이어질 가능성을 측정하는 것으로 추천 시스템을 이용하는 사용자가 시스템 자체를 신뢰하는지를 평가하는 방안이다. 다양성은 단순히 얼마나 정확한 항목을 추천했는가를 넘어 사용자가 선호할만한 다양한 항목을 추천했는가를 평가하는 것으로, 특히 중소유통공동도매물류센터를 이용하는 소매점의 매출 증대를 위해서는 중요한 평가지표로 활용될 수 있다. 향후 연구에서는 추천 시스템의 실질적인 적용을 위해서 보다 다양한 지표로 평가될 필요가 있다. 또 가능하다면 개발된 추천시스템에 따라서 소매점의 구매가 이루어져서 소비자 판매결과까지 확인할 수 있다면 실질적으로 추천시스템의 성능을 평가할 수 있을 것이다.